Uma máquina do tempo chamada Git
Imaginem que, em um projeto, a programadora Alice está desenvolvendo um sistema para um cliente, chegando no fim do ano o cliente pede que o layout do site seja mudado para um tema natalino. Alice então começa a trabalhar no novo layout, ela então cria um diretório novo, chamado sistema-natalino, é neste diretório que Alice fez a cópia do diretório sistema (onde está o código fonte “original”), e onde estará realizando as alterações para o layout de natal do sistema.
Enquanto Alice ainda estava alterando o layout do sistema, o cliente entrou em contato com ela para avisar de um bug no cálculo do frete. E agora? Alice deve realizar a correção do bug em qual diretório? sistema que está com o bug, mas sem as alterações para o natal ou no sistema-natalino, que tem o bug, mas com alterações para o natal incompletas? Alice prefere criar mais um diretório chamado sistema-bug-frete.
Para piorar a situação, a empresa que Alice trabalha contratou mais um programador, o Bob. E ela, agora, deve também treinar Bob para dar manutenção no sistema. Qual diretório Alice deve passar para Bob treinar?

Figura 1 – Depois de um tempo, a equipe acaba com várias versões do sistema, porém qual é a versão que está em produção? Qual é que devemos alterar?
Em pouco tempo a equipe passa a ter vários diretórios, tendo que compartilhar as alterações entre si. Às vezes eles criam diretórios compartilhados em rede, às vezes trocam e-mail e pendrives. No final do ano o versionamento estará uma loucura!
Uma observação antes de iniciar o artigo: e alguns exemplos foram usados comandos no terminal para mostrar o uso do Git, mas se você não gosta ou não quer usar um terminal todas as principais IDEs, editores de códigos e programas específicos para cuidar dos repositórios Git.
A história do versionamento de software
No início (anos 70 e 80, ou até mesmo programadores iniciantes hoje) programadores simplesmente abriam um editor de texto e começavam a programar ali mesmo. Iam salvando o arquivo, criando diretórios e arquivos novos.
Com o tempo alterações eram necessárias, então eles voltavam aos arquivos fontes alteravam, e assim a mesma armadilha ocorria (tanto na década de 70 quanto hoje!): o programador alterava um trecho do programa que funcional, quando terminava descobria que o que tinha feito estava errado, perdendo horas de trabalho! Horas e horas perdidas tanto criando o arquivo quanto alterando o arquivo quanto criando toda a lógica novamente. Sem falar quando algum arquivo era renomeado ou apagado, então estava perdido para sempre!
Criar diretórios (ou pior, várias versões dos arquivos em um mesmo diretório) com cópias também é uma armadilha, com o tempo você acaba se perdendo com tantas versões e assim, novamente, acaba perdendo horas e, muito provavelmente, dias ou semanas de trabalho.
Estes problemas eram apenas para quem estava trabalhando sozinho, quando uma equipe de programadores trabalha com um mesmo código fonte, os problemas só se acumulam mais.
Para compartilhar o código fonte alguns programadores podem querer fazer:
- Criar cópias e distribuir entre os membros da equipe. Enviando por e-mail o diretório compactado, por pendrive, ou mais antigamente, distribuindo CDs e disquetes por aí. Isso só piora os problemas de criar vários diretórios (que agora estão em vários PCs), mas também vai precisar de reuniões com o time para sincronizar todo o trabalho, copiando e colando vários arquivos ou, muito pior ainda, várias partes de programas espalhados por aí. Quanto trabalho!
- Compartilhar um diretório em rede, assim quem está na rede pode acessar um mesmo fonte que todo mundo usa. Então é aí que ocorrem alguns problemas:
- Alice abre o arquivo x, e começa a editar. Enquanto ela edita Bob também abre o mesmo arquivo, como Alice ainda não salvou Bob não têm as alterações de Alice. Alice salva as alterações e alguns minutos depois Bob também. Quando Bob salva o arquivo, como ele estava editando uma versão anterior a que Alice salvou, Bob acaba salvando por cima das alterações de Alice. Todo trabalho que ela fez está perdido!
- O problema anterior pode ser solucionado fazendo com que cada vez que alguém acessa um arquivo, esse arquivo fica bloqueado para acesso. Mas isso acaba criando outro problema: Bob abriu o arquivo e saiu mais cedo aquele dia, sem ter fechado o arquivo, agora Alice precisa editar o mesmo arquivo, como ela vai abrir agora? O arquivo está bloqueado, Bob não está mais na empresa e Alice não consegue trabalhar.
Para resolver esses e outros problemas, foram criados os sistemas de controle de versão (Version Control Systems – VCS).
A seguir uma linha do tempo resumida dos VCS:
Sistemas focados em arquivos, apenas em uma máquina, muitíssimo parecido ou igual à ideia de manter as cópias de arquivos que Alice e Bob fazem, mas de maneira automatizada:
1972 SCCS: Criado pela Bell Labs, rodava apenas em UNIX e apenas para um usuário, nada de compartilhar o fonte. Apenas arquivos e texto.
1982 RCS: Cross-platform, apenas um usuário pode editar o arquivo por vez, não era seguro, pois, usuários podem editar o histórico de alterações. Apenas arquivos e texto.

Figura 2 – Resumidamente, como estes sistemas funcionam. Uma base de versões guarda todas as versões, a última versão é a primeira da fila, a primeira versão que aponta para segunda, e assim até chegar na última versão. O checkout é onde programamos, o checkout aponta para a última versão.
Fonte: Pro Git book.
Sistemas centralizados, um servidor para todos dominar! Muitos continuam com a ideia de fazer a gestão de diretórios e arquivos, automatizando o processo de guardar várias cópias:
1986 CVS: Primeiro sistema com repositório central, com foco em arquivos. Pode ser usado por vários usuários. Ao invés de manter cópias do diretório, mantinha cópias dos arquivos alterados, diminuindo o espaço em disco necessário, que era muito caro na época.
1995 Perforce: Conseguia cuidar do código fonte e dos binários, solução focada em grandes projetos e equipes, os principais clientes eram grandes empresas de software.
2000 Subversion: Prometia ser uma solução melhor que o CVS com a criação de branches (o que nunca foi um problema de verdade, já que os merges era o real problema), mas nunca conseguiu arrumar os problemas que o CVS tinha.
2004 Microsoft Team Fundation Server: Suporta não apenas versionamento de software, mas também de bugs, tarefas e testes.

Figura 3 – Sistemas centralizados. A base de versões fica em um servidor, enquanto os checkouts dos computadores apontam para uma mesma versão.
Fonte: Pro Git book.
Sistemas Distribuídos, cada máquina têm um ou mais repositórios individuais, podendo compartilhar com um servidor ou com outros usuários individuais, este compartilhamento não é obrigatório:
2000 BitKeeper: Usado como o VCS no início do Linux Kernel, tinha uma licença Open Source, mas em 2005 mudaram para software proprietário cobrando pela licença, isso fez com que vários usuários (programadores e empresas) deixassem de usar o sistema, incluindo o projeto do Linux Kernel.
Em resposta a mudança de licença do BitKeeper, sugiram os sistemas Mercurial e Git:
2005 Mercurial: Altar performance, escalabilidade e descentralização são os pilares do Mercurial. Facebook, W3C e Mozilla são algumas empresas que usam o Mercurial atualmente.
2005 Git: Criado pelo Linus Torvalds para substituir o BitKeeper, atualmente é um dos principais VCS usado pelo mercado.

Figura 4 – VCS distribuídos. Cada computador tem sua própria base de versões. O servidor também tem uma base e cada computador pode compartilhar entre si.
Fonte: Pro Git book.
Atualmente os 5 mais usados são Git e Mercurial, para quem deseja uma solução distribuída ou Perforce, Microsoft Team Fundation Server (TFS), Subversion para quem deseja uma solução centralizada.
Alguns sistemas como Subversion e CVS oferecem a opção de instalar plugins ou até mesmo versões com suporte ao Git e Mercurial.
O Git
Até 2005 o projeto do Linux Kernel utilizava o BitKeeper, era um sistema proprietário que era distribuído gratuitamente, como VCS padrão. Então neste ano a empresa responsável pelo BitKeeper resolveu não mais distribuir gratuitamente o sistema, cobrando uma valor por licença.
Foi assim que Linus Torvalds, que já observava alguns problemas com o BitKeeper, começou a programar o Git como alternativa. Inicialmente escrito em C o Git faz uma série de comparações com os arquivos e apenas salva as diferenças entre os arquivos, otimizando a quantidade de armazenamento necessária.
Além disso, cada usuário mantêm suas alterações localmente, podendo, opcionalmente, enviar ou copiar alterações de um servidor, ou simplesmente enviar, ou copiar outro repositório local de outra máquina, sem a necessidade de um servidor. Este é um ponto muito importante do Git, muitas pessoas pensam que é necessário um servidor para salvar o repositório, mas a figura do servidor é totalmente opcional. Muitos projetos utilizam o servidor Git como uma forma simples e segura de distribuir o código fonte entre uma equipe.
Algumas vantagens do Git são:
- Velocidade: operações são executadas quase que instantaneamente.
- Simples: Poucos conceitos para aprender e configurações para fazer. Uma vez tudo preparado o sistema toma conta do seu código.
- Forte suporte para desenvolvimento não linear: é possível trabalhar, literalmente, com mais de milhares de versões diferentes. Tudo de maneira simples, prática e rápida.
- Para o grande e para o pequeno: Programadores sozinhos podem tirar muito proveito do Git sem ter que lidar com complexidades, assim como os grande projetos com milhares de desenvolvedores e equipes.
Como o Git guarda seu código
Um fluxo simples para trabalhar com o Git é: criar um repositório local e ir adicionando as alterações e enviar para o repositório local.
Os comandos git init , git add e git commit irão cirar o repositório local, adicionar as alterações e enviar para o repositório local. A imagem a seguir ilustra esse fluxo.

Figura 5 – Fluxo básico de trabalho com o Git.
git init: isso basicamente irá criar um diretório .git no diretório onde o comando foi realizado. Este diretório ficará invisível, e será nele que o Git irá guardar todas as alterações feitas.
git add: este comando, seguido do nome dos arquivos que foram alterados, irá adicionar esses arquivos em um estágio anterior ao repositório.
git commit: todas as alterações que estão em um estágio antes do repositório irão para o repositório.
Ao realizar um commit o Git irá fazer um snapshot do seus arquivos, diretórios e subdiretórios, a partir do diretório onde está o .git (onde foi realizado o comando git init). O commit anterior irá apontar para o novo commit.
Estas alterações são guardadas dentro do diretório .git, terão um identificador próprio para cada, caso queira voltar em uma versão especifica, terá que usar este identificador. Por questões de performance apenas os arquivos que foram alterados serão guardados, os demais terão a referência da última versão.
A imagem a seguir explica melhor este fluxo:
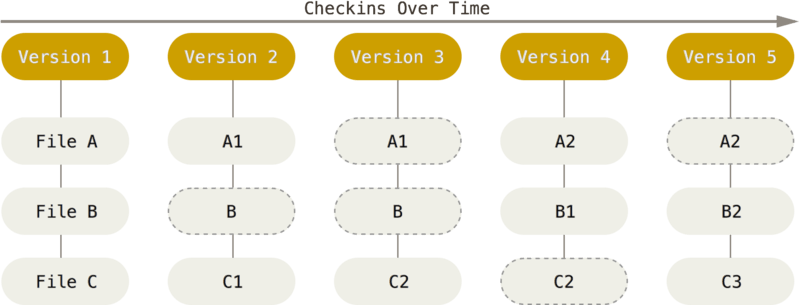
Figura 6 – Fluxo de versionamento Git. A cada novo commit o Git criará uma versão nova. As borda pontilhada representam os arquivos inalterados, eles são referências ao anterior.
Fonte: Pro Git book.
O básico do Git
Como já vimos como o Git guarda nosso código fonte, vamos nos aprofundar em todas as etapas para que isso ocorra.

Figura 7 – Fluxo que o nosso código fonte irá passar.
Fonte: Pro Git book.
O código irá passar por 3 locais: working directory, staging area e repository.
Working directory: local onde você irá programar, testar e alterar o código fonte. Nenhum comando git aqui.
Staging area: Quando adicionamos as alterações ao Git (git add) o nosso código irá para esta área intermediária, podemos ir adicionando as alterações gradualmente ou todas de uma vez só, não importa, elas ficarão todas acumuladas. As alterações ficando aqui não estão versionadas! Estão apenas esperando a vez para entrar no repositório.
Repository: Quando commitamos as alterações (git commit) todas as alteraçãoes que estão no staging (staging area) irão para o repositório, nenhum alteração do Warking directory irá para o repositório com o commit! O git irá realizar um checksum das alterações para gerar um identificador único daquele commit.
Uma vez com todas as alterações no repositório, é possível utilizar o comando git checkout com o identificador de qualquer commit para voltar a uma versão específica. Com isso o git irá restaurar todos os arquivos do working directory para a versão desejada.
Branches e mergings
Talvez o maior diferencial do git seja a possibilidade de trabalhar várias versões ao mesmo tempo, sem grandes problemas.
Digamos que você está em um projeto e precisa fazer uma feature nova, mas não deseja correr o risco de alterar o código que está funcionando. Você pode criar um branch, que irá criar um linha de commits paralela ao master, a linha principal.
Quando criamos um repositório e fazemos commits, sem criar nenhum branch, o git já irá criar um branch, o principal ou master, é a partir dele que vamos criar nosso branch para a nova feature. Será necessário apenas um comando git checkout -b nova-feature, você irá criar o branch e mudar para ele, explicando o comando fica:
- git checkout: comando usado para alterar para outro branch;
- -b: opção usada para criar o branch novo
- nova-feature: nome do branch.

Figura 8 – Como os commits se comportam quando temos brenches e merges, indo do commit 0 (C0) atá o commit 12 (C12).
Agora com o novo branch você realiza uma alteração, volta para o master, volta para o branch etc.
Ao final você decide que terminou a nova feature, agora só juntar com o master e continuar programando. Para fazer isso apenas use os comandos abaixo:
- git chackout master: este comando irá mudar você para o branch master;
- git merge nova-feature: este comando irá juntar seu código do branch nova-feature com o master, sobrando apenas o master.
5 Git em equipes
Uma vantagem de usar um sistema de versionamento moderno é poder trabalhar em equipe com várias pessoas.
O git por ser descentralizado, permite que os programadores possam testar várias alterações diferentes, mantendo o versionamento, mas sem interferir no trabalho dos outros.
No Git você pode trabalhar localmente, apenas você fazendo commits, enviar seu diretório raiz para alguém (via pendrive, e-mail, compartilhamento em rede etc) ou usar um servidor para enviar estas alterações.
Para ter este servidor temos algumas opções:
- GitHub: é uma plataforma totalmente online, onde é possível criar repositórios de código (privados ou abertos), procurar por outros projetos e colaborar com projetos open-source. A ferramenta é gratuita, oferecendo ferramentas visuais para acompanhar commits e branches. Além disso, também é possível abrir issures com bugs ou sugestões de alterações, pull requests enviando códigos para um repositório que você quer contribuir, integrações e muito mais!
- Bitbucket: Muito similar ao GitHub, é muito utilizado por que não deseja ter um repositório público, apenas permitindo o acesso de poucas pessoas ao código fonte.
- GitLab: permite fazer muito do que o GitHub e Bitbucket permitem e, ao mesmo tempo, você pode usar a plataforma ou baixar e instalar sua própria instalação em casa, ou empresa.
- SourceForge: O mais antigo desta lista, além de oferecer opções para o Git, também aceita uma variedade grande de outros versionadores.
Você irá usar, basicamente, 3 comandos aqui:
- git clone: Este comando seguido do link do repositório irá fazer o download de todo o repositório em sua máquina.
- git push: Uma vez com todas as alterações comitadas, com este comando, seguido nome do repositório e o branch que as alterações irão para o servidor.
- git pull: Este comando seguido do nome do repositório e o branch desejado, irá atualizar seu repositório local, baixando as últimas alterações.
Considerações finais
Neste artigo apenas fiz uma introdução superficial de como o Git funciona e como ele pode ajudar você no dia a dia como programador. Os comandos que listei aqui já são o suficiente para conseguir utilizar o Git. Mas se você precisar levantar ou gerenciar um servidor Git, terá que estudar e se aprofundar muito mais na ferramenta.
Para quem não quer parar por aqui, eu sugiro 5 lugares para se aprofundar mais:
- Meu vídeo com uma apresentação do Git e alguns comandos básicos: https://youtu.be/T3bjVrU3WcI?t=2803;
- Os dois vídeos do Fábio Akita, onde ele demonstra os conceitos mais fundamentais do Git e boas práticas com a ferramenta; https://www.youtube.com/watch?v=6Czd1Yetaac e https://www.youtube.com/watch?v=6OokP-NE49k
- A apresentação com o próprio Linus Torvalds explicando como e o porque ele criou o Git, e inglês; https://www.youtube.com/watch?v=4XpnKHJAok8
- Pro Git Book: o livro oficial do Git, é gratuito e você pode baixar em PDB, EPUB ou MOBI, ou ler online mesmo. Apesar da tradução para o português, apenas os dois primeiros capítulos foram traduzimos, mesmo assim é mais que o suficiente para trabalhar no dia a dia. https://git-scm.com/book/pt-br/v2
Referências
Crypto Couple. Alice & Bob: A History of The World’s Most Famous Cryptographic Couple. Disponível em: http://cryptocouple.com/
Michael Lehman. The history of version control. Disponível em: https://www.linkedin.com/learning/learning-software-version-control/the-history-of-version-control?autoplay=true&trk=learning-course_table-of-contents_video&upsellOrderOrigin=default_guest_learning
Fábio Akita. Entendendo GIT | (não é um tutorial!). Disponível em: https://www.youtube.com/watch?v=6Czd1Yetaac
Linus Torvalds. Tech Talk: Linus Torvalds on git. Disponível em: https://www.youtube.com/watch?v=4XpnKHJAok8
Scott Chacon e Ben Straub. Pro Git book. Disponível em: https://git-scm.com/book/pt-br/v2





